# Getting the version of Python we are using :
import sys
sys.version_infosys.version_info(major=3, minor=12, micro=4, releaselevel='final', serial=0)In this article, I will try to do linear regressions with Python. This is also an occasion for me to try Python with Quarto.
This section is dedicated to using Python with Quarto, since this website was done using Quarto (if you want to know more about it, you can check their documentation here and this project of mine). If you do not use Quarto, you can just skip this section.
The Quarto Markdown format (with the .qmd extension) allows to embed code and text, formatted with Markdown. To work with Python code in Quarto, we first have to use an engine that supports Python. For that, we can use python3 or jupyter for examples. Thus, in our YAML header, we would enter :
---
engine: python3
# or :
engine: jupyter
---We can check our engines with quarto with the command quarto check. This function is designed to “verify [the] correct functioning of Quarto installation” (from its description in documentation). Running it returns the versions of different kernels that we can use.
Finally, to include python code in our Quarto file, we can write :
```{python}
# Some python code here
```For example :
# Getting the version of Python we are using :
import sys
sys.version_infosys.version_info(major=3, minor=12, micro=4, releaselevel='final', serial=0)Here, we are for example using Python 3.12.
Depending on the engine we are using, we can also make use of other languages in the same Quarto document. Specifying the python3 engine in the YAML header of our Quarto document, we can run Julia and R in it. For that, we need packages, such as JuliaCall for using Julia with R.
Testing Julia yields :
# Getting the version of Julia we are using :
using InteractiveUtils
InteractiveUtils.versioninfo()Julia Version 1.10.3
Commit 0b4590a550 (2024-04-30 10:59 UTC)
Build Info:
Built by Homebrew (v1.10.3)
Note: This is an unofficial build, please report bugs to the project
responsible for this build and not to the Julia project unless you can
reproduce the issue using official builds available at https://julialang.org/downloads
Platform Info:
OS: macOS (arm64-apple-darwin23.4.0)
CPU: 8 × Apple M1
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-15.0.7 (ORCJIT, apple-m1)
Threads: 1 default, 0 interactive, 1 GC (on 4 virtual cores)
Environment:
DYLD_FALLBACK_LIBRARY_PATH = /Library/Frameworks/R.framework/Resources/lib:/Library/Java/JavaVirtualMachines/jdk-11.0.18+10/Contents/Home/lib/serverTesting R yields :
# Getting the version of R we are using :
version _
platform aarch64-apple-darwin20
arch aarch64
os darwin20
system aarch64, darwin20
status
major 4
minor 4.0
year 2024
month 04
day 24
svn rev 86474
language R
version.string R version 4.4.0 (2024-04-24)
nickname Puppy Cup Since the rest of the article will exclusively be using Python, we will not mention further details of engines in Quarto. It is however interesting to keep in mind that Quarto allows this multiple integration.
This section of the article treats how to do a simple linear regression with Python. We will first generate random data, we will plot it, and we will then add the linear regression to our plot.
I found two main libraries to generate random data in Python. The first one is the random library, and the second one is the numpy library.
With the random library, we can use the random method to generate by default a float number between 0 and 1. A way to create a vector of 100 random values is to use the random method between square brackets, followed by the for instruction, similar to the one in Julia. This will generate a list of size fixed, such that :
import random
y = ([random.random() for _ in range(100)])
x = ([random.random()*y[_] for _ in range(100)])Let us comment a bit this code :
random.random() refers to the method random() inside the random library._ combined with for loops to iterated for a set number of times. By default, the _ symbol just refers to the last variable in memory of Python, but it can also be used like that.range() function allows to create a range object in Python. More specifically :[It] return[s] an object that produces a sequence of integers from start (inclusive) to stop (exclusive) by step. Range(i, j) produces i, i+1, i+2, …, j-1. Start defaults to 0, and stop is omitted! range(4) produces 0, 1, 2, 3. These are exactly the valid indices for a list of 4 elements. When step is given, it specifies the increment (or decrement).
A second way of generating random data is using the numpy library. For that, we use the numpy.random.rand() method :
import numpy
numpy.random.rand(100)array([0.00592745, 0.75294248, 0.94689826, 0.47642028, 0.11962005,
0.52470106, 0.60702635, 0.15253373, 0.53457452, 0.38565149,
0.64664118, 0.52782941, 0.1863171 , 0.62393744, 0.47887005,
0.51752405, 0.6082846 , 0.94538496, 0.15588617, 0.93843073,
0.71304326, 0.91281546, 0.15744652, 0.65390069, 0.90430497,
0.02007971, 0.90876743, 0.7371541 , 0.13214819, 0.77117829,
0.41983029, 0.42378729, 0.68161776, 0.77530917, 0.10258949,
0.64014087, 0.92515723, 0.81516093, 0.32943734, 0.88071784,
0.45455588, 0.66861511, 0.82865439, 0.56225488, 0.9957281 ,
0.52904564, 0.47166687, 0.88949489, 0.45428736, 0.97020451,
0.99314305, 0.67423413, 0.56184371, 0.41641916, 0.54561917,
0.93896844, 0.09701167, 0.62007889, 0.87678115, 0.39321745,
0.9872945 , 0.97044126, 0.54605077, 0.51073665, 0.00533591,
0.97947303, 0.23759523, 0.22853751, 0.13700576, 0.9933836 ,
0.82715814, 0.56069471, 0.58494474, 0.93326851, 0.97248153,
0.90951482, 0.02044552, 0.01536296, 0.09132653, 0.31115691,
0.3089081 , 0.24117981, 0.42406074, 0.77607162, 0.07922152,
0.43397369, 0.36773676, 0.91578712, 0.4391219 , 0.46481153,
0.84583504, 0.11902362, 0.97803419, 0.98239256, 0.39096067,
0.39562847, 0.69702822, 0.84916839, 0.85820585, 0.07123363])Here, the numpy.random.rand() method also generates a random real number between 0 and 1. We are going to stick with the first x variable created for the rest of the section.
Now that we generated some data, let us plot it. To do that, we can use the matplotlib library. More specifically, we are going to use pyplot inside matplotlib, and are thus going to import matplotlib.pyplot :
import matplotlib.pyplot
matplotlib.pyplot.scatter(x,y)
scatter() method of matplotlib.pyplot allows to plot a scatterplot with two vectors of the same size.The
scatter()“method” can also be considered as a function. This distinction seems to also exist in other programming languages and is definitely worth understanding. For the sake of linear regressions, it does not matter for now to develop a full understanding of this distinction. In the rest of this article, we will thus stick to the “method” term without further explanation.
We are now going to fit our statistical model with our randomly generated values. In order for us to do that, we can use the scipy.stats library. This library has a linregress() method that allows to compute the OLS estimates to explain the second variable with the first one :
import scipy
model = scipy.stats.linregress(x,y)
modelLinregressResult(slope=np.float64(0.8383718326044476), intercept=np.float64(0.30883317915377173), rvalue=np.float64(0.6159824384646858), pvalue=np.float64(9.024229215374189e-12), stderr=np.float64(0.10830516572266864), intercept_stderr=np.float64(0.03237551409033611))We see that the scipy.stats.linregress() method returns a five elements object. To make this method easier to use, we could generate five variables, define a function with those variables and plot a line based on this function :
# We define the five variables from the linregress() method :
slope, intercept, r, p, std_err = scipy.stats.linregress(x, y)
# We define a function returning a linear function with the slope and the intercept :
def myfunc(x):
return slope * x + intercept
# We create a list object with the list() function that takes as an argument a map object, based on our function and on the variable x :
mymodel = list(map(myfunc, x))
mymodel[np.float64(0.3466552962850944), np.float64(0.4855711228389237), np.float64(0.9147031170175356), np.float64(0.5153160299254063), np.float64(0.3801609990790563), np.float64(0.6044597742873725), np.float64(0.8592707674606043), np.float64(0.36509600545338833), np.float64(0.5527195718240848), np.float64(0.5240474317193224), np.float64(0.6014795199237659), np.float64(0.42070431481441095), np.float64(0.3281109864632415), np.float64(0.609338479700958), np.float64(0.5272774936883462), np.float64(0.49793336361061025), np.float64(0.6615576168832237), np.float64(0.48558369820808656), np.float64(0.682856174322561), np.float64(0.7340434195846064), np.float64(0.5627113232349656), np.float64(0.32278236816126854), np.float64(0.5929799171046213), np.float64(0.35278841098901403), np.float64(0.3580677536604607), np.float64(0.42191435405309263), np.float64(0.3238418122945764), np.float64(0.3191886742819142), np.float64(0.3568292775067544), np.float64(0.32757438236782), np.float64(0.32671680069225056), np.float64(0.42326584087775343), np.float64(0.3301253898513797), np.float64(0.49109681714494313), np.float64(0.44458311312708415), np.float64(0.5199585587348523), np.float64(0.9186022591677041), np.float64(0.39114282592853183), np.float64(0.4014183383452378), np.float64(0.4877972869989182), np.float64(0.3266773853988873), np.float64(0.4588845589667885), np.float64(0.5815321192975246), np.float64(0.5075743754991987), np.float64(0.46377760017945563), np.float64(0.3574396105070033), np.float64(0.39249417206726944), np.float64(0.488752927533466), np.float64(0.35569069788803687), np.float64(0.49822895229055497), np.float64(0.5161923540876256), np.float64(0.5088533951852636), np.float64(0.769034375640042), np.float64(0.6326334342149869), np.float64(1.0423321590360448), np.float64(0.3296848512011278), np.float64(0.3707922844586858), np.float64(0.4266797387634848), np.float64(0.33652341146276105), np.float64(0.39743971330310107), np.float64(0.3336311390693917), np.float64(0.5564567995066856), np.float64(0.376091444906386), np.float64(0.45090231896434735), np.float64(0.5040838302265498), np.float64(0.4051622523445217), np.float64(0.3226383239044324), np.float64(0.33191401608324494), np.float64(0.4666930634968537), np.float64(0.570707699127708), np.float64(0.5617582353940804), np.float64(0.3124068143973404), np.float64(0.5292769029282633), np.float64(0.3203018487632795), np.float64(0.7373582721485279), np.float64(0.36890927811192537), np.float64(0.5325929851471497), np.float64(0.6323717424690725), np.float64(0.932503917572861), np.float64(0.33708525383560667), np.float64(0.6526942091151531), np.float64(0.35715817364214664), np.float64(1.015109148788574), np.float64(0.32887962550451877), np.float64(0.7060221022682294), np.float64(0.339489680159918), np.float64(0.6722012746136157), np.float64(0.7056671726580602), np.float64(0.745471258289146), np.float64(0.4308133963682357), np.float64(0.33121240452941486), np.float64(0.37579615641214226), np.float64(0.40511754269860345), np.float64(0.40202405377269135), np.float64(0.7391566857584171), np.float64(0.5956863712448213), np.float64(0.4803225716002546), np.float64(0.3907379210536772), np.float64(0.4214984627624902), np.float64(0.3109604583787798)]The definition of the variable mymodel is worth explaning a bit more in details. The list() function is used to create a list object (which is considered one of the most versatile objects in Python), like the c() function creates a vector in R. The map() function returns a map object, defined as :
map(func, *iterables) –> map object Make an iterator that computes the function using arguments from each of the iterables. Stops when the shortest iterable is exhausted.
in the Python documentation.
Now, if we want to add this line to our plot, we can run :
matplotlib.pyplot.scatter(x,y)
matplotlib.pyplot.plot(x, mymodel)
While it is curious that the variable mymodel is displayed as a continuous line, it works, so I am fine with this solution for now.
If we want only the more relevant information, we can choose to only work with the two first elements of the array, and plot it, we can do in a more concise way :
def f(x):
return scipy.stats.linregress(x, y)[1]+numpy.dot(x,scipy.stats.linregress(x, y)[0])
float(scipy.stats.linregress(x, y)[1]),float(scipy.stats.linregress(x, y)[0])(0.30883317915377173, 0.8383718326044476)matplotlib.pyplot.scatter(x,y)
matplotlib.pyplot.plot(x, f(x))
We note here that we are using the numpy.dot() method from the numpy library. This method allows us to do the dot product of two different matrixes. In our case, doing only x * scipy.stats.linregress(x,y)[0] would have returned an error, since x and the other term are not of the same dimension. This method thus allows to avoid this error by vectorizing the multiplication.
Now that we covered a how to perform a simple linear regression with Python, let us move to a multiple linear regression.
In this section, we are going to perform a multiple linear regression. First, we are going to generate data and fit our model. Then, we will plot a static scatter plot, and finally a 3D rotatable plot.
First, let us generate some random data and fit our model.
To generate random data, we can do :
# We randomly generate four variables of length 100 :
w,x,y,z = (numpy.dot([random.random() for _ in range(100)],_) for _ in (1,2,3,4))
# Just to check the length :
len(y)100To run a multinomial linear regression that satisfies the OLS equation, we could use several libraries. Let us say that we want to explain the z variable by x and y.
One approach that seems to be widely used is to use the sklearn library. More specifically, we could use the sklearn.linear_model package :
import sklearn.linear_model
# We create an object that regroups x, y and w :
regressors = numpy.column_stack((x,y,w))
# We create the object 'model' that has the LinearRegression() class from the sklearn.linear_model package :
model = sklearn.linear_model.LinearRegression()
# Fit the model to the data
model.fit(regressors, z)LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
LinearRegression()
model.coef_array([0.02372518, 0.22686716, 0.08769466])model.intercept_np.float64(1.5537197507494207)The model.intercept_ value is the intercept of z, and the coefficients are consistent with the regressors object. The first one corresponds to the effect of x, the second to the effect of y, and the last one to the effect of w.
To get a nicer display and final object, we can alternatively use the statsmodels library.
import statsmodels.api
# Create the object and specify an intercept :
regressors = statsmodels.api.add_constant(regressors)
model = statsmodels.api.OLS(z,regressors)
# Run the model :
results = model.fit()
# Print the regression table :
print(results.summary()) OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.030
Model: OLS Adj. R-squared: -0.000
Method: Least Squares F-statistic: 0.9966
Date: Fri, 05 Jul 2024 Prob (F-statistic): 0.398
Time: 14:07:22 Log-Likelihood: -152.78
No. Observations: 100 AIC: 313.6
Df Residuals: 96 BIC: 324.0
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.5537 0.358 4.342 0.000 0.843 2.264
x1 0.0237 0.202 0.118 0.907 -0.377 0.424
x2 0.2269 0.135 1.684 0.095 -0.041 0.494
x3 0.0877 0.400 0.219 0.827 -0.706 0.881
==============================================================================
Omnibus: 17.960 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.139
Skew: 0.179 Prob(JB): 0.0766
Kurtosis: 1.949 Cond. No. 9.43
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.We can also access to the itnercept and the coefficients directly, by doing :
results.paramsarray([1.55371975, 0.02372518, 0.22686716, 0.08769466])If we now want to limit ourselves to a four dimensional problem, we can plot 3D graphs with colors representing the fourth dimension. In this section, we are first going to plot a static graph.
# We first create the framework of a plot, that we name "figure" :
figure = matplotlib.pyplot.figure()
# In this figure, we are going to use the add_subplot method to create a three dimensional projection :
projection = figure.add_subplot(projection='3d')
# In this three dimensional space, we are going to project our points in a scatterplot way.
# The argument 'c' stands for the color of the points :
projection.scatter(x,y,z, c = w)
# Finally, we give each of our axis a name :
projection.set_xlabel("X")
projection.set_ylabel("Y")
projection.set_zlabel("Z")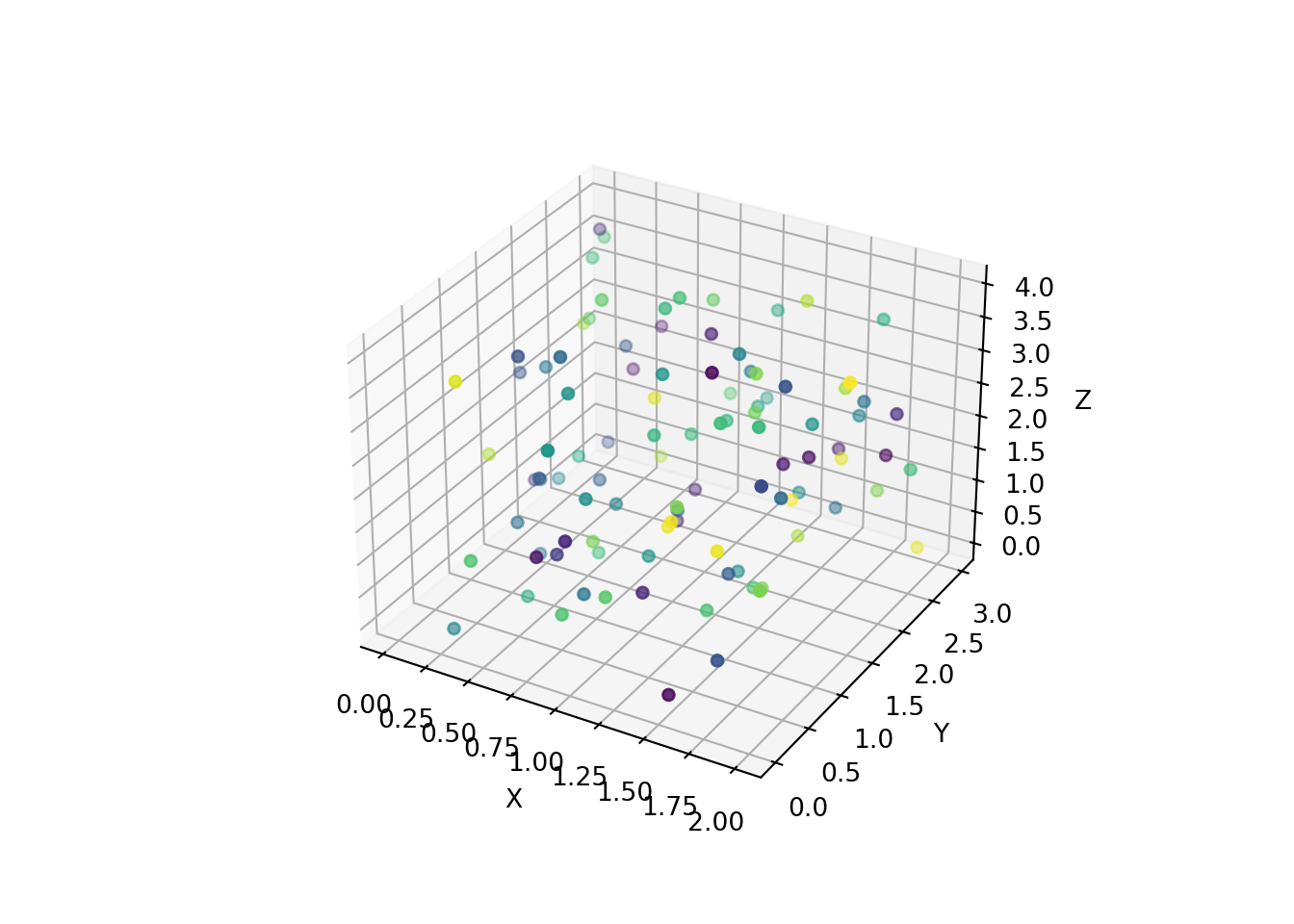
The syntax of this example can be a bit hard to understand at first, but is required when using matplotlib.pyplot library.
Now it’s time for a rotatable plot, like in the previous article. Fortunately, the plotly library does also exist for Python, which is great, because I did not find any other library that yielded a similar result. However, to use plotly, we need the pandas library.
We can thus create a dataframe object from a dictionary with the four previously created vectors. If we only want to display a 3D scatter plot, we can run :
import plotly.express
import pandas
# We create a four columns dataframe with our four previously generated vectors :
data = {'c1':[x],'c2':[y],'c3':[z],'c4':[w]}
X = pandas.DataFrame(data)
fig = plotly.express.scatter_3d(X, x,y,z, color=w)
fig.show()We note that this yields a plot with similar features to the ones obtained in the previous article with Julia. The reason for that is that both obtained plots are done using the plotly library.
For the rest of the section, we are going to limit ourselves to only two regressands, excluding the w variable, since the display will be easier to understand this way :
X = numpy.column_stack((x,y))
X = statsmodels.api.add_constant(X)
model = statsmodels.api.OLS(z,X)
results = model.fit()
print(results.summary()) OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.030
Model: OLS Adj. R-squared: 0.010
Method: Least Squares F-statistic: 1.485
Date: Fri, 05 Jul 2024 Prob (F-statistic): 0.232
Time: 14:07:23 Log-Likelihood: -152.81
No. Observations: 100 AIC: 311.6
Df Residuals: 97 BIC: 319.4
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.5915 0.312 5.099 0.000 0.972 2.211
x1 0.0273 0.200 0.136 0.892 -0.370 0.425
x2 0.2292 0.134 1.715 0.090 -0.036 0.494
==============================================================================
Omnibus: 18.620 Durbin-Watson: 2.015
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.252
Skew: 0.186 Prob(JB): 0.0724
Kurtosis: 1.941 Cond. No. 6.97
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.Now, we need more lines to plot a surface. More specifically, we are going to use plotly.graph_objects and make use of the meshgrid method :
import plotly.graph_objects
# We first store the information of our regression :
intercept, coef1, coef2 = results.params
# We then create meshgrids for x,y, and z :
x_range = numpy.linspace(x.min(), x.max(), 10)
y_range = numpy.linspace(y.min(), y.max(), 10)
x_grid, y_grid = numpy.meshgrid(x_range, y_range)
z_grid = intercept + coef1 * x_grid + coef2 * y_grid
# We now generate a surface object with the grids we just created
surface = plotly.graph_objects.Surface(
x=x_grid, y=y_grid, z=z_grid,
colorscale='Viridis', opacity=0.5
)
# We create a scatter object, to be able to plot it with the surface :
scatter = plotly.graph_objects.Scatter3d(
x=x, y=y, z=z,
mode='markers',
marker=dict(size=5, color=w, colorscale='Viridis')
)
# We create a figure object, with the scatter and surface tha we just generated :
fig = plotly.graph_objects.Figure(data = [scatter, surface])
# We display the figure :
fig.show()This looks satisfactory. I even manage to plot the points with the surface of the regression in the 3D plot.